



This past year I tried to build a few different companies. Here I’m sharing:
what I’ve learned,
what I’m doing next,
and what I might be able to help you with. (yes you!)
Company Number 1: Padex
Padex.io helps people read patents faster and more accurately by connecting or “hyperlinking” portions of the document so you can have a more interactive reading experience and skip the scrolling back and forth.

This idea was born during a conversation with my friend Bill Messner about his experiences being an IP expert witness. Bill and I were having coffee one morning at Amesbury Bakehouse (great coffee btw!) and we were sharing what each of us does for a living. Bill asked me if there was a way to short-circuit the “scrolling back and forth” between figures and text when he’s reading patents. Having used pre-trained models to solve this kind of problem before, in particular, LayoutLM and edge prediction models, I could see this was feasible.
The market
We struggled to find interest among independent practices. It also seems extra hard to sell to legal. 4 of the 5 of the legal tech founders that I met with were Lawyers first. They onboarded all their existing clientele to their products. All of them told me this market is particularly hard to sell to.
We tried going bigger. In October 2022, we found a company primarily focused on “Freedom to Operate”. Their operation was labor intensive with 1000s of people reading patents and highlighting pertinent information. This company mentioned acquiring or doing an exclusive license with us so they had our attention!
We delivered two new features. One was to make a 10x improvement on “in text” numbered element names and ids***. Then in our second meeting, it was clear they were going to try to build this internally.
I still think there’s an opportunity put Padex to use for another domain, something that isn’t patents. Anywhere where you have sparse text that you want to extract and or relate to some other text would find this product useful. As it only uses the bitmap information, you can pretty much throw anything at padex.io and it’ll parse for you.
The amount of graphical documents that are produced is surprisingly large and PDFs aren’t going away either. We’re definitely keeping this on the shelf. Maybe it’s not useful now, but we think there’s a place for it eventually.
Tech Stack:
pytorch (e.g. graph neural nets for connecting figure IDs and Figures together)
AWS Textract (OCR)
***This was a pretty big change that involved making it possible for LayoutLM to take in more text than is allowed by the underlying LLM model (BERT). Anyone who is using LayoutLM will appreciate this!
Company Number 2: Label Labs
While building padex.io we created a workflow that I believe is tremendously useful. This was to treat the creation of a label schema as a highly iterative process.
When most ML practitioners build models, changing your labeled data is an uncommon event, and usually, that change is simply adding more data to it.
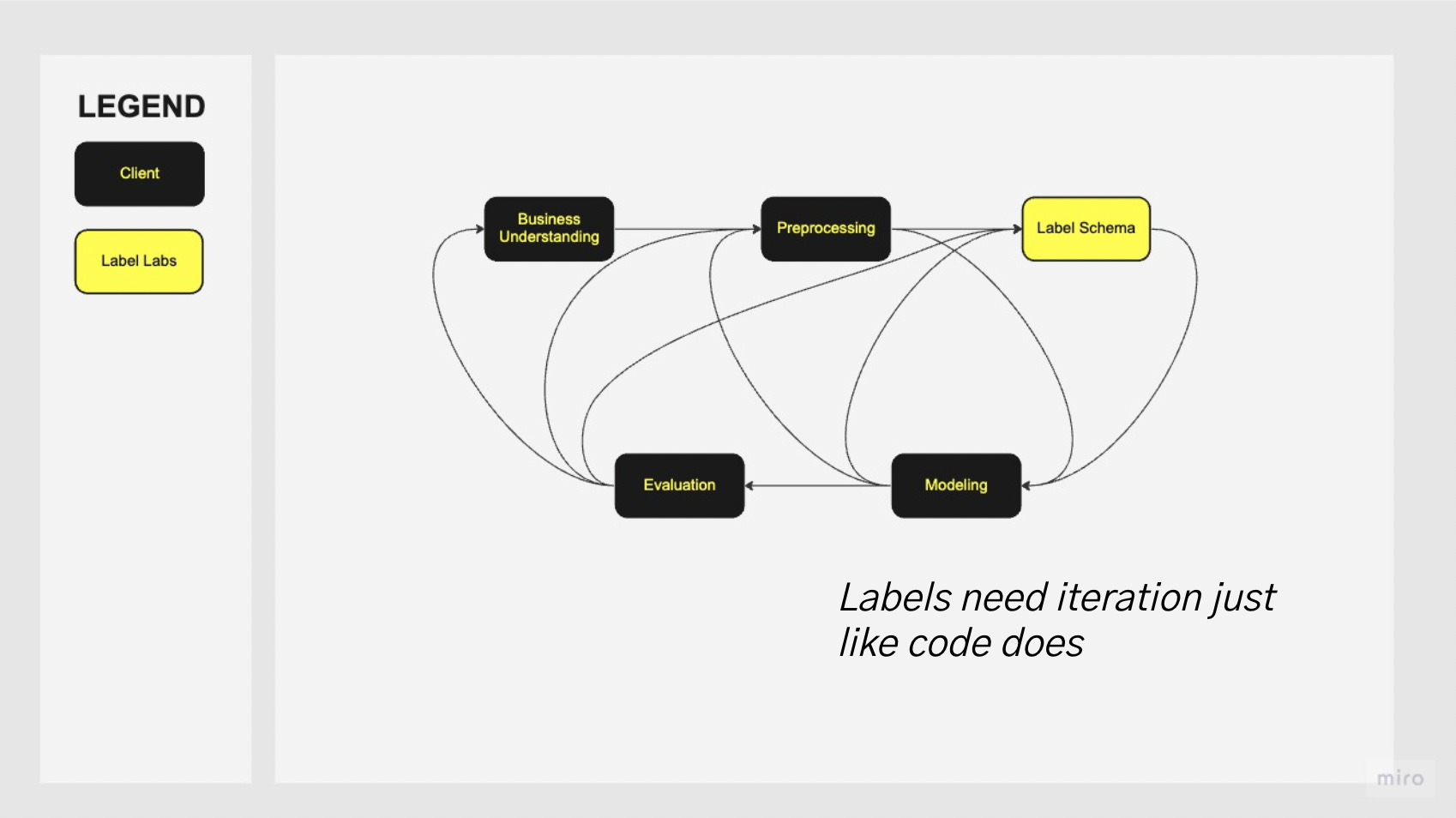
While building padex.io our model iteration emphasized:
label schema iteration
label quality
Over:
label quantity
model tuning
Two examples of label schema iteration:
1. Label-Schema expanded: Figure IDs
Labeling Figure IDs turned out to be significantly more complicated than our 1st iteration which was merely drawing a box around anything that was “figure ID” related.

2. Label-Schema expanded: Relationships Included as a Label
After discovering we couldn’t create a simple rule based on proximity to link numbered elements to figures, we encoded edges between bounding boxes which we used to train an edge prediction model.

In both of these examples above, there was a quantitative evaluation of results (e.g. did Recall improve?). But, instead of looking at the model, or the amount of data on hand, we changed the job the model does, which can only be done by changing your label schema. «« This requires relabeling a lot of data, something we have developed workflows specifically to handle. It also requires way more communication than what you might get at AWS Groundtruth or Scale.ai. You’re no longer working with a data labeler, you’re working with an Annotation Manager.
The market
Most of the resistance to Label Labs’ offering was around pricing. Everyone wanted to know the cost per label. Most customers that I had spoken with didn’t want to commit to hiring someone embedded into their team.
Margins are incredibly small when factoring in what startups are willing to pay an Annotation manager. Most seem to see this as commodity-level work, which to some degree I understand. But many large companies like Apple and Facebook have embraced Annotation Management as a role within ML organizations.
At a minimum I’ll be bringing this paradigm with me to future organizations. I’ve toyed with the idea of simply turning this into an annotation management recruiting agency.
Tech Stack:
Label Schema (google docs)
Company Number 3: Yentabot.ai
Raechel, Jonah, and I placed 1st at Miami Hack Week and won best use of OpenAI with Yentabot.ai, a Conversational AI Knowledge Base.

We were chatting about GPT3 and an upcoming https://www.miamihackweek.com/. Obviously, this is a trendy tech wave. But who doesn’t like trying to catch a wave once in a while?
Imagine not needing to write anything down to transfer information? Yentabot will listen to your team in slack, zoom, git, etc. and remember everything. Instead of creating documentation, here is a new paradigm…
Just In Time Documentation
“Ryan: @Yentabot Can you create onboarding documentation for someone to be able to contribute as a software engineer to our organization?”
“Yentabot: Please see this README.md I’ve just written”
When you’re done with the documentation delete it. It’s already out of date anyway! :)
Hack Week
We all spent the entire week together in our apartment in South Kendall Florida. We’d wake up and get a little exercise in and breakfast as a team, then we’d work from 10am until midnight. We did this every day until the big day. It’s amazing what you can do in one week of deliberate work!
Future of Yentabot
Growing a business like this can be a bit of a slog at the beginning as we try to find product market fit. We’ve had ~10’s of installations. We’re still in very early stages and have a long way to go though! This is a very new space and it’s not straightforward or guaranteed if this is feasible as a business.
Tech Stack:
What’s next?
Pause
After winning in Miami Hack Week, I had someone ask me as I was getting off stage if I could help their company setup a similar retrieval/text-generation system “but for <their thing>”.
I offered to help for 1 - 2 hours per week, but I couldn’t justify giving much more when what we built seemed to have so much momentum! It’s been almost two months. It’s clear the path is slower and uncertain for Yentabot. Not giving up on it, just reallocating some resources!
Open source
I’ve been contributing to the Llama-index(formerly gpt_index) library and will continue to do so. I’ll be writing about what I’m discovering on this substack along the way.
Jerry et al. are moving fast on this library, if you’re in this space you’d do well to take a look at it and consider contributing! There’s a lot of opportunities here!
I’m helping clients use GPT
I’d like to help people build these wondering retrieval + text-generation machines! Are you experimenting with:
Chat agents that take actions?
Tool use from speech (e.g. accessing multiple tools/APIs from one chat interface)
Something else?
Hit me up! I’d love to hear what you want to build!